While metrictank persists timeseries data to a store such as cassandra or bigtable, it can - and should - serve most data out of memory. It has two mechanisms to support this: the ring buffers, and the chunk-cache. These features are complementary to each other, and are described in more detail below.
The ring buffer is simply a list of chunks - one for each series - that holds the latest data for each series that has been ingested (or generated, for rollup series).
You can configure how many chunks to retain (numchunks).
The ring buffer can be useful to assure data that may be needed is in memory, in these cases:
- you know a majority of your queries hits the most recent data of a given time window (e.g. last 2 hours, last day), you know this is unlikely to change and true for the vast majority of your metrics.
- keep secondaries able to satisfy queries from RAM for the most recent data of cold (infrequently queried) series, even if the primary is not able to save its chunks instantly, if it crashed and needs to be restarted or if you're having a store outage so that chunks can't be loaded or saved. Note that this does not apply for hot data: data queried frequently enough (at least as frequent as their chunkspan) will be added to the chunk cache automatically (see below) and not require storage lookups.
Note:
- the last (current) chunk is always a "work in progress", so depending on what time it is, it may be anywhere between empty and full.
- when metrictank starts up, it will not refill the ring buffer with data from the store. They only fill based on data that comes in. But once data has been seen, the buffer will keep the most chunks it can, until data is expired when series haven't been seen in a while.
Both of these make it tricky to articulate how much data is in the ringbuffer for a given series. But (numchunks-1) * chunkspan is the conservative approximation which is valid in the typical case (a warmed up metrictank that's ingesting fresh data).
For keeping a "hot cache" of frequently accessed data in a more flexible way, this is not an effective solution, since the same numchunks is applied to all raw series
(and aggregation settings are applied to all series in the same fashion, so a given rollup frequency will have the same numchunks for all series)
So unless you're confident your metrics are all subject to queries of the same timeranges, and that they are predictable, you should look at the chunk cache below.
The goal of the chunk cache is to offload read workload from the store. Any data chunks fetched from the store are added to the chunk cache. But also, more interestingly, chunks expired out of the ring buffers will automatically be added to the chunk cache if the chunk before it is also in the cache. In other words, for series we know to be "hot" (queried frequently enough so that their data is kept in the chunk cache) we will try to avoid a roundtrip to the store before adding the chunks to the cache. This can be especially useful when it takes long for the primary to persist chunks, or when there is a storage outage. The chunk cache has a configurable maximum size, within that size it tries to always keep the most often queried data by using an LRU mechanism that evicts the Least Recently Used chunks.
The effectiveness of the chunk cache largely depends on the common query patterns and the configured max-size value:
If a small number of metrics gets queried often, the chunk cache will be effective because it can serve most requests out of its memory.
On the other hand, if most queries involve metrics that have not been queried for a long time and if they are only queried a small number of times,
then Metrictank will need to fallback to the store more often.
See config documentation for an overview and basic explanation of what the config values are. Most of them are in storage-schemas.conf Some of the values related to chunking and compression are a bit harder to tune, so this section will explain in more detail.
chunkspan is how long of a timeframe should be covered by your chunks. E.g. you could store anywhere between 1 second to 24 hours worth of data in a chunk.
numchunks is simply up to how many chunks should be retained in the ring buffers per metric. Queries for data not in the ringbuffer will hit the chunk-cache-fronted store.
Note that these are defined for each archive individually (raw and rollups)
Chunkspans can be set to one of 1sec, 5sec, 10sec, 15sec, 20sec, 30sec, 60sec, 90sec, 2min, 3min, 5min, 10min, 15min, 20min, 30min, 45min, 1h, 90min, 2h, 150min, 3h, 4h, 5h, 6h, 7h, 8h, 9h, 10h, 12h, 15h, 18h, 24h.
This list can be extended in the future.
The standard recommendation is at least 120 points per chunk.
The more points are contained within a chunk, the more efficiently the compression can work. After about 120 points per chunk, the returns diminish. For more details, see the go-tsz eval program or the results table
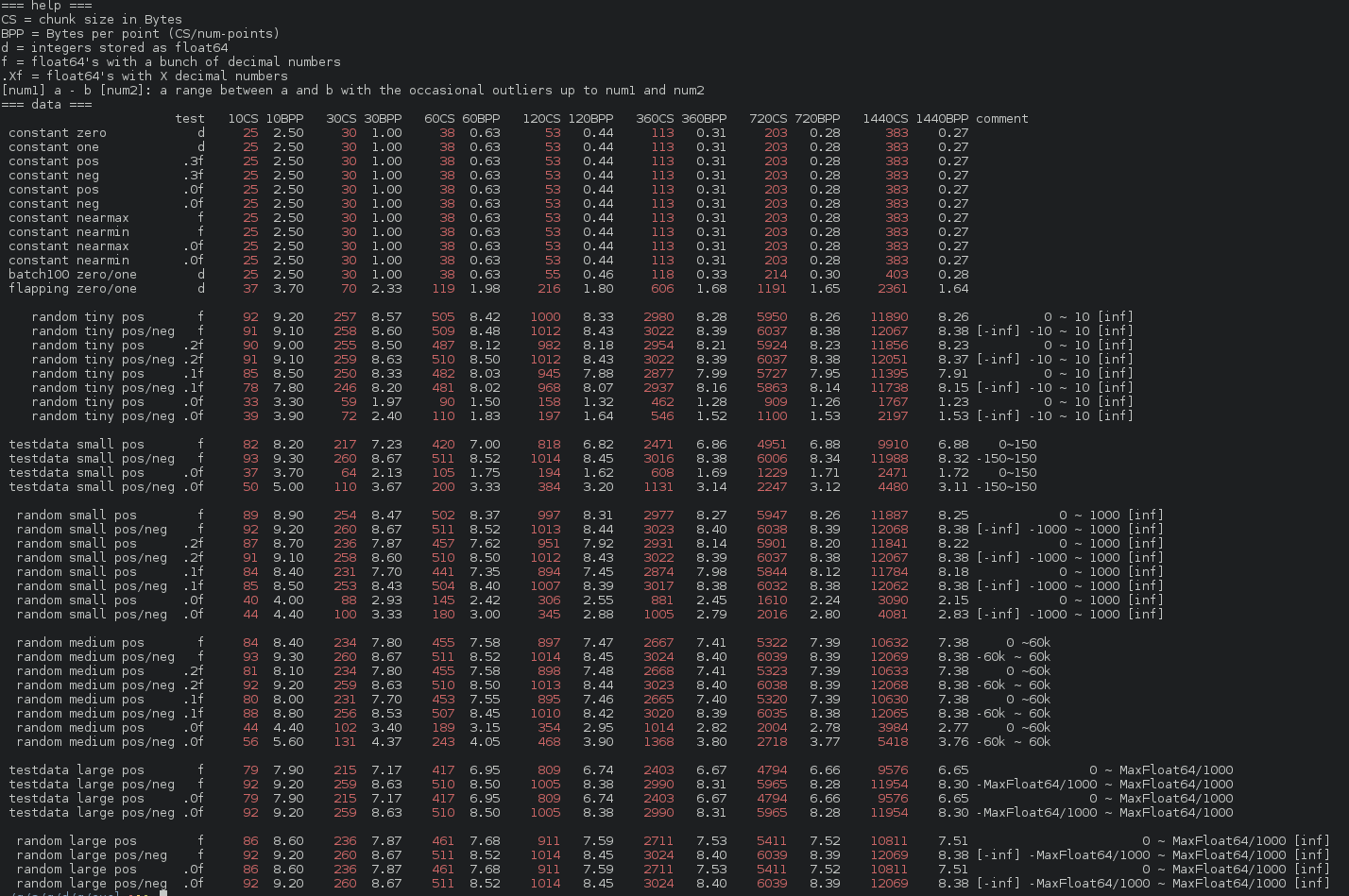{kind=link}
Longer chunks with more points mean a lower rate of chunk saves in the store. There is probably an upper limit where the store becomes unhappy with large chunksizes, but we haven't seen that yet.
Chunks come with a memory overhead (for the internal datastructure and bookkeeping). Longer chunks with more data reduce the memory overhead. Though this rarely seems to be a real concern. Longer chunks however do force you to keep more data in RAM. Let's say you want to keep 1h worth of data in RAM. With a chunksize of 1h you need to keep 2 chunks in RAM (because the current chunk becomes empty at every start of a 1h interval), which in worst case leads up to 2h worth of data. With a chunksize of 1min you need to keep 61 chunks in RAM, worst case being 61 minutes.
Longer chunk sizes means a longer backfill of more older data (e.g. with kafka oldest offset), or a longer warm up if you only consume realtime data (e.g. with kafka offset latest).
If garbage collection is a problem (which can be analyzed with the metrictank grafana dashboard), then this can be reduced by picking longer chunks and keeping fewer of them. The more chunks you have, the more they need to be scanned by the Go garbage collector. We plan to keep working on performance and memory management and hope to make this factor less and less relevant over time.
In principle, you need just 1 chunk for each series. However:
- when the data stream moves into a new chunk, secondary nodes would drop the previous chunk and query the store But the primary needs some time to save the chunk to the store. Based on your deployment this could take anywhere between milliseconds or many minutes. Possibly even an hour or more. As you don't want to slam the store with requests at each chunk clear, you should probably use a numchunks of 2, or a numchunks that lets you retain data in memory for however long it takes to persist data. (though the chunk cache alleviates this concern for hot data, see above).
- The ringbuffers can be useful to let you deal with crashes or outages of your primary node. If your primary went down, or for whatever reason cannot save data, then you won't even feel it if the ringbuffers can "clear the gap" between in memory data and older data in the store. So we advise to think about how fast your organisation could resolve a potential primary outage, and then set your parameters such that
(numchunks-1) * chunkspanis more than that. (again, with a sufficiently large cache, this is only a concern for cold data)
If you roll-up data for archival storage, those chunks will also be in memory as per your configuration.
Querying for large timeframes will use the consolidated chunks in RAM, and keeping
extra raw (or higher-resolution) data in RAM becomes pointless, putting an upper bound on how many chunks to keep.
See Consolidation
E.g. if your most common data interval is 10s, then your chunks should be at least 120*10s=20min long.
If you think your organisation will need up to 2 hours to resolve a primary failure, then you need always at least 6 such chunks in memory,
so you will need numchunks of 7 or more, because the current one may be empty.
chunkspan = 20min
numchunks = 7
Any older data that is often queried will be within the chunk-cache.
Normally, in the tank, we close and persist chunks when data comes in for a newer chunk. But this may not always happen (e.g. you stop sending data for a given series), as such we have a GC mechanism that is configured at the top of the metrictank config file.
chunks (raw and rollups) are closed and persisted when at a GC run:
- they haven't been written to for
chunk-max-stale(default: 1h) or more. - and we should have started a new chunk 15 min ago or more (if the stream was realtime)
For this mechanism to work, kafka retention should be: largest raw chunk span + gc interval + chunk-max-stale + safety window for manual interventions upon a crash, and time needed to drain write queues Why? consider what happens in a worst case scenario: we might do a GC check right before chunk-max-stale is hit, so we must wait until next GC run. at which point GC kicks in and starts filling up the write queue. but just before the chunk is moved from write queue into persistent store, and the instance crashes. and we need manual intervention to get a new writer up and running