| marp | theme | class | paginate | style | backgroundColor | backgroundImage |
|---|---|---|---|---|---|---|
true |
default |
invert |
true |
img[alt~="center"] {
display: block;
margin: 0 auto;
}
|
→ covers the operations and processes that keep an application running in production
- Deployments must be reliable and predictable
- Automate deployments to reduce the chance of human error. Fast and routine deployment processes won't slow down the release of new features or bug fixes.
- Quickly roll back or roll forward if an update has problems.
→ reduce percentage of toil
- ensure consistency
- centralize mistakes
- identify issues quickly
- maximize employee productivity
→ Infrastructure Deployment & Configuration, Operational Tasks
- Optimize build and release processes
- Monitor system and understand operational health
- Microservices & DevOps Model
- Rehearse recovery and practice failure
- Embrace continuous operational improvement
- Landing zones in place
- Keep environments as similar as possible
- Continuous Integration & Continuous Delivery
- Integrate tests
- Automated Testing
- Unit testing
- Smoke Testing
- Infrastructure as Code
- Integrate in process: Peer review, automated scanning
- Avoid configuration drift
- Easily manage multiple environments
- Make frequent, small, reversible changes
- Access control and audit changes
- Declarative approach toolings: ARM Templates, CloudFormation, Terraform, ...
- Configuration as Code
- Bootstrap & patch automation
- Tools:
- VM extensions, cloud-init, PowerShell Desired State Configuration (DSC), Chef, Puppet
- Event response
- Use processes for event, incident, and problem management
- Have a process per alert
- Prioritize operational events based on business impact
- Define escalation paths
- Automate responses to events
- Monitor build and release processes
- Monitor infrastructure and application health
- Track availability of the system and its components
- Track application telemetry
- Track user activity
- Understand workload health to meet business goals
- SLAs
- Compliance
- Monitor infrastructure and application health
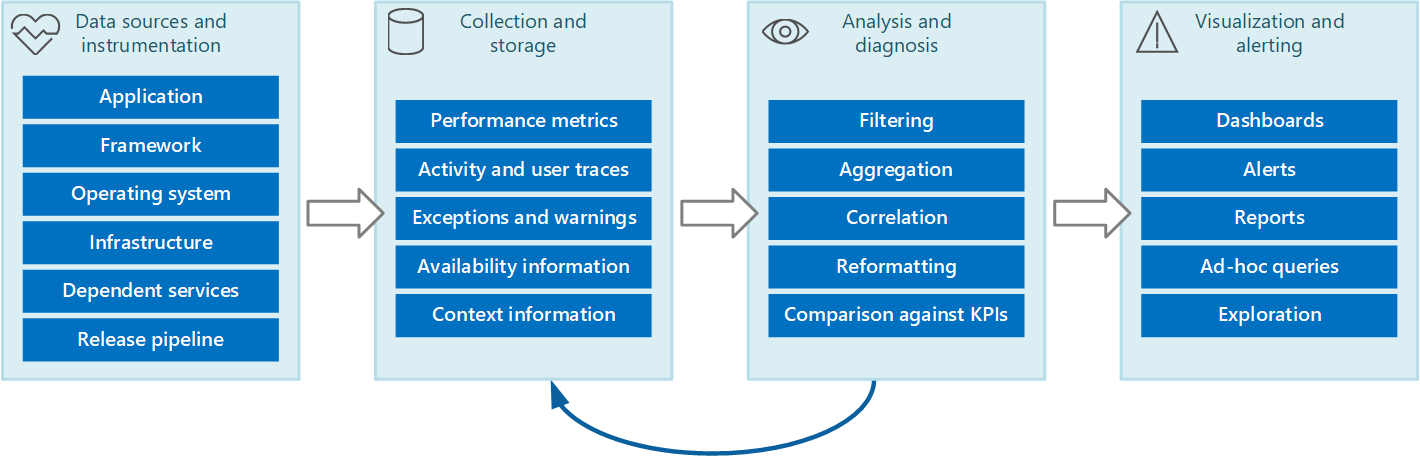
→ Monitoring and diagnostics are crucial.
Best practices:
- Correlate application and resource level logs
- Define clear retention times on storage for cold analysis
- Analyze long-term trends analyzed to predict operational issues
- Microservices design
- Independent components
- Deploy, patch, update systems independently
- Reduce blast radius
- Strive for a true DevOps Model
- Create multidisciplinary teams that now work together with shared and efficient practices and tools
- DevOps model positions the responsibility of operations with developers

Separated Application Engineering and Operations (AEO) and Infrastructure Engineering and Operations (IEO)


{kind=link}
Relationship & Owners:
- Resources have identified owners
- Processes and procedures have identified owners
- Team members know what they are responsible for
- Mechanisms exist to identify responsibility and ownership
- Rehearse recovery
- Practice failure
- Fault injection
- Business Continuity Drills
- Pre-mortem exercises
- Use rollbacks of PaaS offerings (or k8s)
- Evolve processes
- Regular review and validation
- Share knowledge across teams
- Post-incident analysis
- Optimizing inefficiencies through automation
- Operational tasks
- Rule of three
→ ability of the systzem to adapt to changes
- ability of your workload to scale to meet the demands placed on it by users in an efficient manner
- Understand the challenges of distributed architectures
- Scaling
- Design for scaling
- Scaling issues
- Scale as a unit
- Take advantage of platform autoscaling features
- Improve scalability with session affinity
- Be aware of antipatterns
- e.g. Improper instantiation, Noisy Neightbour, No Caching
- Scaling
- Understand the challenges of distributed architectures
- Build with microservices
- Asynchronous Request-Reply pattern / Asynchronuous programming
- Process faster by queuing and batching requests
- Implement background jobs
- Go global
- Choose the right service
- Data storage
- Correct VM size
- Use serverless architectures if possible
- Run performance testing
- Establish baselines
- During all stages of the development and deployment life cycle
- Load and stress testing
- Shared team responsibility
- Configure the environment based on testing results to sustain performance efficiency
- Plan for a load buffer to accommodate random spikes without overloading the infrastructure
- Continuously monitor the application and the supporting infrastructure
- Use distributed tracing to build and visualize end-to-end transaction flows for the application.
- With Scaling in mind
- Store logs and key metrics of critical components for statistical evaluation and predicting trends.
- Invest in capacity planning
- Preemptive scaling based on trends
- Prepare infrastructure for large-scale events
- Use metrics to fine-tune scaling